De Dados Tabulares a Embeddings: Repensando a Engenharia de Features
Todo cientista de dados já passou por isso: horas criando features, normalizando valores, codificando categorias e tratando outliers. Por décadas, a engenharia de features foi arte e ciência ao mesmo tempo — um ritual necessário antes de alimentar algoritmos de machine learning.
Mas e se houvesse outro caminho?
E se pudéssemos eliminar a engenharia de features tradicional, convertendo dados tabulares brutos em texto significativo e depois em embeddings vetoriais que capturam as relações semânticas entre os pontos de dados?
É exatamente isso que o projeto tab2vec propõe explorar.
A Grande Ideia
O conceito é deceptivamente simples:
- Converter dados tabulares (numéricos e categóricos) em descrições de texto legíveis por humanos
- Transformar essas descrições em embeddings vetoriais usando modelos de linguagem
- Treinar modelos de machine learning usando esses embeddings em vez das features brutas
Essa abordagem oferece diversas vantagens potenciais:
- Reduzir o tempo de engenharia de features automatizando o processo de conversão
- Capturar relações semânticas que a codificação tradicional não percebe
- Aplicar transfer learning de grandes modelos de linguagem a dados tabulares
- Padronizar o pré-processamento entre diferentes tipos de datasets
- Integração nativa com bancos de dados vetoriais, permitindo recuperar dados tabulares por similaridade semântica em vez de filtros ou engines de LLM-para-SQL
O Problema das Abordagens Tradicionais
Ao trabalhar com dados tabulares, tratamos cada feature de forma independente: normalizamos as numéricas, aplicamos one-hot encoding nas categóricas e criamos interações entre elas. Mas essa abordagem não captura as ricas relações semânticas que podem existir nos dados.
Considere a previsão de preços de imóveis: a relação entre “bairro” e “nota de qualidade” não são apenas duas features independentes — há contexto ali que a codificação tradicional não consegue capturar.
O Framework tab2vec
Para testar essa ideia adequadamente, construí o tab2vec, um framework para comparar diferentes abordagens de codificação de dados tabulares como texto para embeddings. A arquitetura é modular:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Dados │ │ Codificador │ │ Gerador de │ │ Modelo │
│ Tabulares │───▶│ de Texto │───▶│ Embeddings │───▶│ de ML │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘Cada componente é plugável, permitindo experimentar diferentes estratégias de codificação de texto, modelos de embeddings, algoritmos de ML e datasets.
Experimentos Iniciais com Dados Sintéticos
Antes de trabalhar com datasets reais, rodei benchmarks em datasets sintéticos para estabelecer baselines e validar a abordagem.
Geração dos Datasets Sintéticos
Criei múltiplos tipos de datasets:
- Datasets abstratos com features puramente numéricas (sem significado inerente)
- Datasets semânticos simulando domínios como:
- Dados financeiros de clientes (renda, score de crédito, índice de endividamento)
- Métricas de saúde (pressão arterial, colesterol, IMC)
- Imóveis (tamanho, quartos, qualidade do bairro)
Baseline vs. Performance com Embeddings
| Tipo de Dataset | Tarefa | Features Diretas | Embeddings de Texto |
|---|---|---|---|
| Abstrato | Classificação | 89% acurácia | 50,5% acurácia |
| Abstrato | Regressão | R² = 0,956 | R² = 0,492 |
| Semântico Saúde | Classificação | 97% acurácia | 90% acurácia |
| Semântico Saúde | Regressão | R² = 0,998 | R² = 0,903 |
| Semântico Cliente | Classificação | 98,5% acurácia | 76% acurácia |
| Semântico Cliente | Regressão | R² = 0,904 | R² = 0,785 |
| Imóveis Semântico | Regressão | R² = 0,964 | R² = 0,762 |
| Ames Housing | Regressão | R² = 0,973 | R² = 0,716 → 0,840* |
* Após otimização de templates, discutida abaixo
O padrão ficou claro: embeddings de texto têm dificuldade com dados numéricos abstratos, mas funcionam razoavelmente bem em domínios semanticamente significativos. A diferença foi maior nos dados abstratos (38,5 pontos percentuais na classificação), mas se reduziu consideravelmente nos semânticos (7 pontos percentuais na classificação de saúde).
A Importância do Contexto Semântico
Considere esta codificação abstrata:
Sample with age: 0.4249783431863819, income: 1.8881671003483596,
education level: -1.6293918257219868, credit score: 0.4655578248059355,
account balance: -2.0121677332442007...Os valores padronizados não carregam nenhum significado semântico que um modelo de embeddings possa aproveitar. Em contraste:
Patient is a 42-year-old with normal blood pressure (118/75),
slightly elevated cholesterol (210), and a BMI of 26.4 (overweight).Isso fornece contexto rico que modelos de embeddings entendem a partir do pré-treinamento.
Principais Aprendizados com Dados Sintéticos
- Valores numéricos brutos performam mal: números padronizados sem contexto são essencialmente sem significado para modelos de embeddings
- Terminologia específica do domínio importa: termos médicos, conceitos financeiros e jargão imobiliário são melhor capturados
- Nomear features melhora os resultados:
age: 42superafeature_1: 42 - Formatação legível por humanos ajuda: descrições em linguagem natural superam listas separadas por vírgulas
- Relações semânticas se transferem: conhecimento pré-existente nos modelos (ex: colesterol alto é ruim) se transfere para as previsões
O Experimento com o Dataset Ames Housing
O Baseline
Usando CatBoost diretamente nas features: R² de 0,97. Uma barra alta.
Primeira Tentativa: Codificação Básica de Texto
Property: {property_type} with {bedrooms} bedrooms, {bathrooms} bathrooms,
{area} sq ft, {age} years old. Quality rating: {quality}/10.
Features: {has_garage} garage, {has_pool} pool.
Neighborhood: {neighborhood}. Price per sq ft: ${price_per_sqft}.Usando nomic-embed-text + CatBoost: R² de 0,71 — razoável, mas bem abaixo do baseline.
A Jornada de Otimização de Templates
A forma como representamos os dados como texto impacta a performance do modelo? Essa pergunta levou a três fases de experimentação.
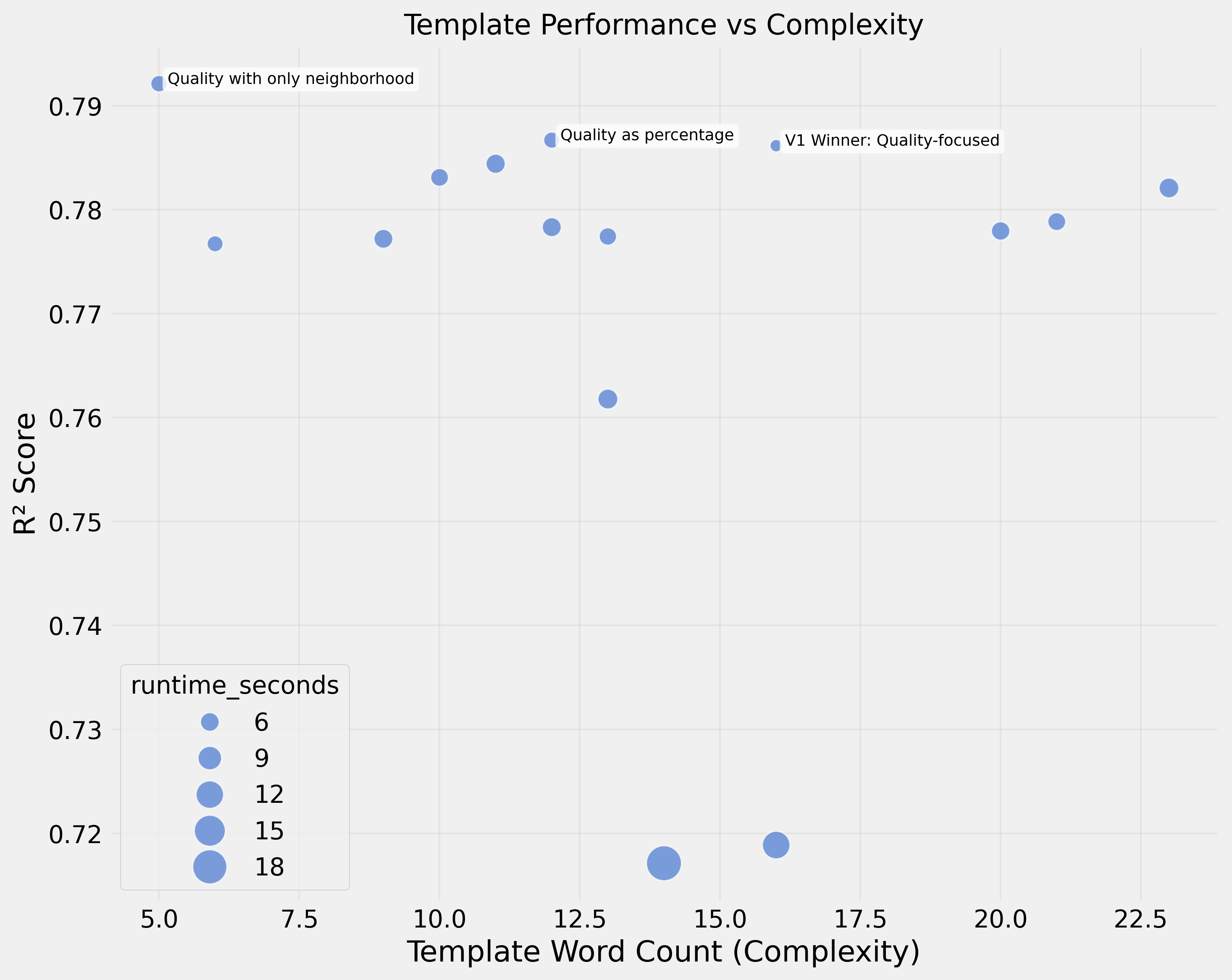
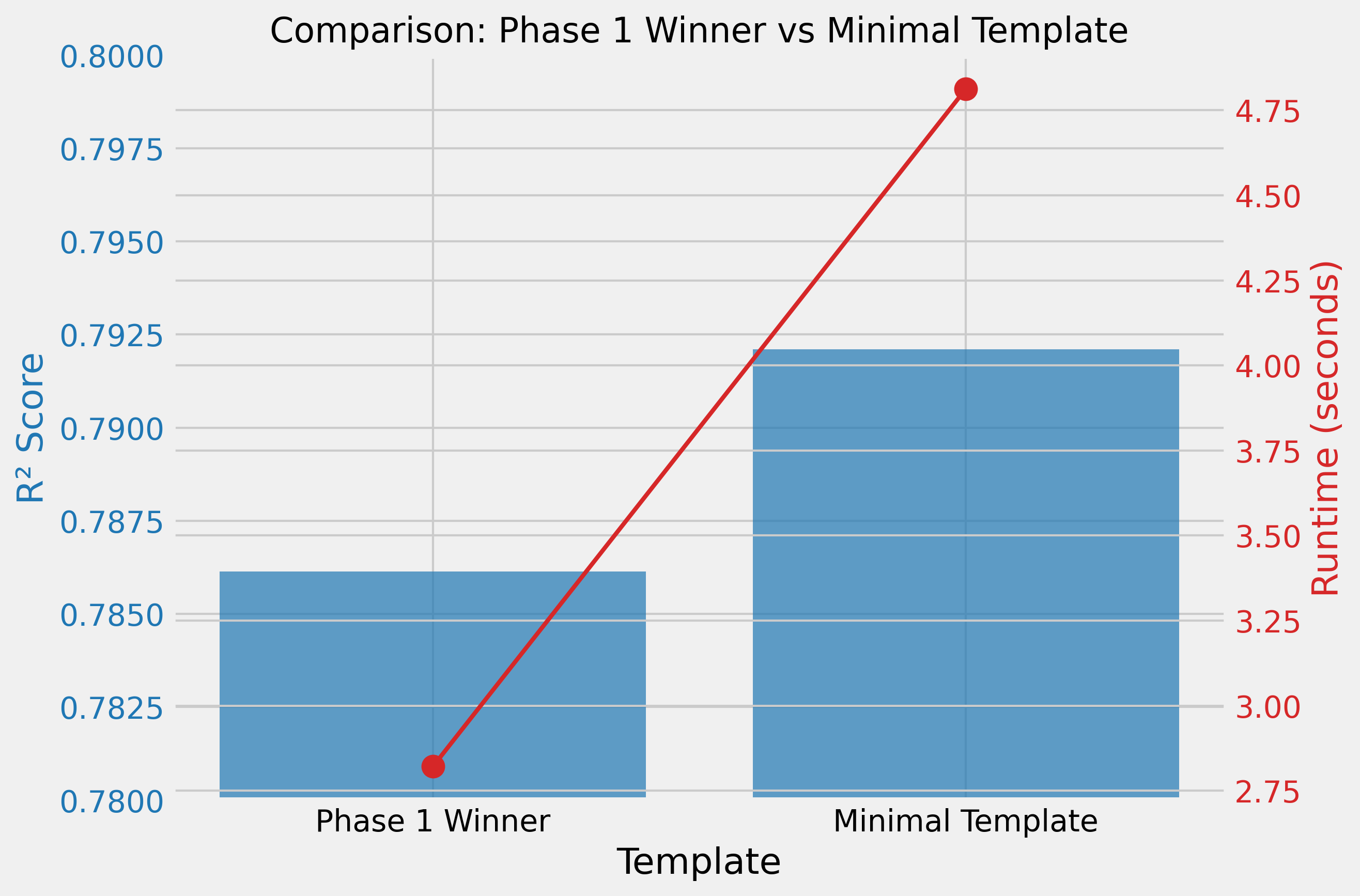
Fase 1: O Design do Template Importa
Testando 21 templates diferentes, ficou claro que o design impacta significativamente a performance. O melhor template alcançou R² de 0,79.
O vencedor focou em notas de qualidade e features categóricas, omitindo tamanho e detalhes de cômodos:
Quality rating: {quality}/10. Features include: Garage ({has_garage}),
Swimming pool ({has_pool}). Property type: {property_type},
located in {neighborhood}.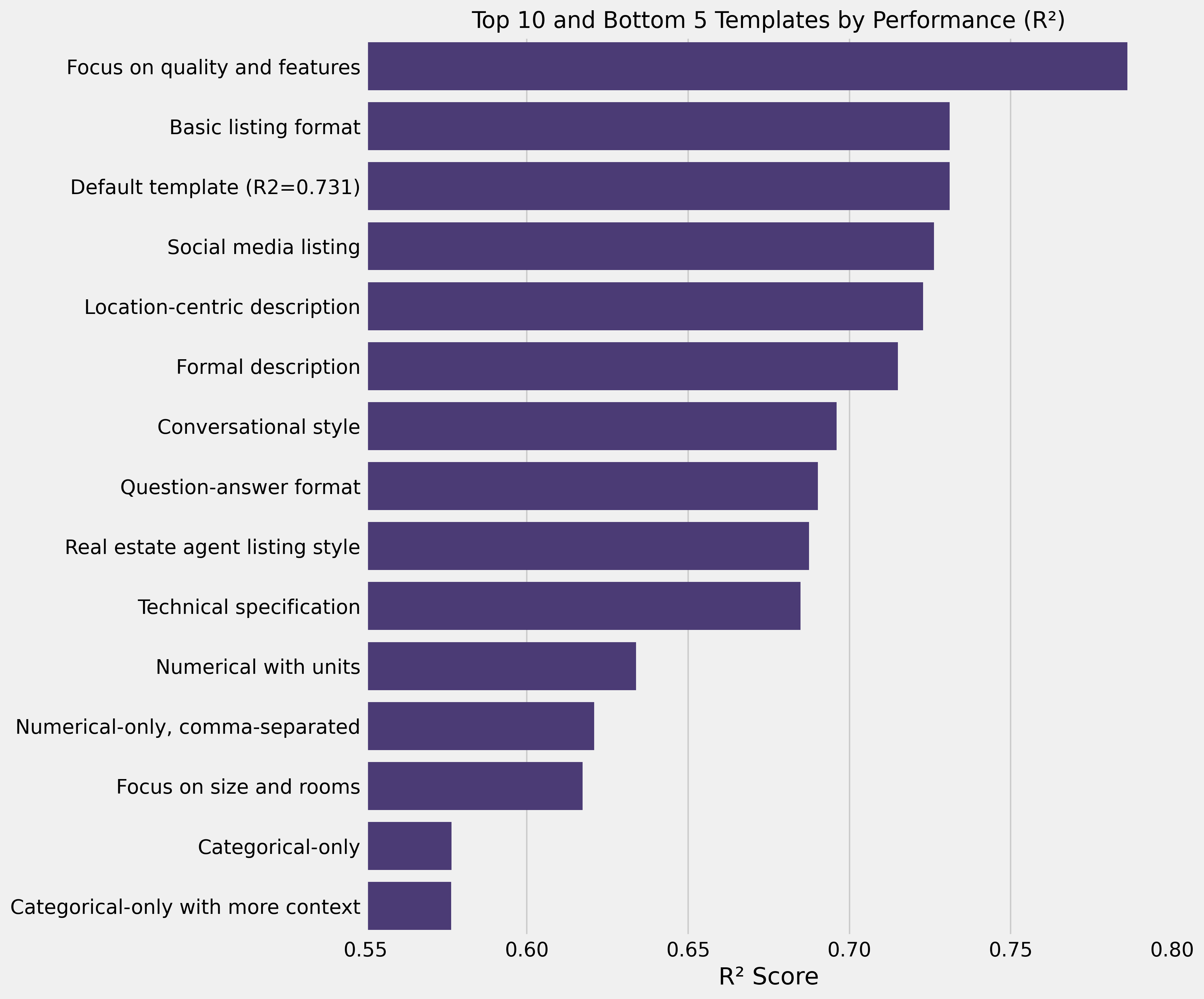
Fase 2: Minimalismo é a Chave
Um template com apenas qualidade + bairro superou os mais complexos:
Quality rating: {quality}/10. Neighborhood: {neighborhood}.R² de 0,79 — às vezes menos é mais.
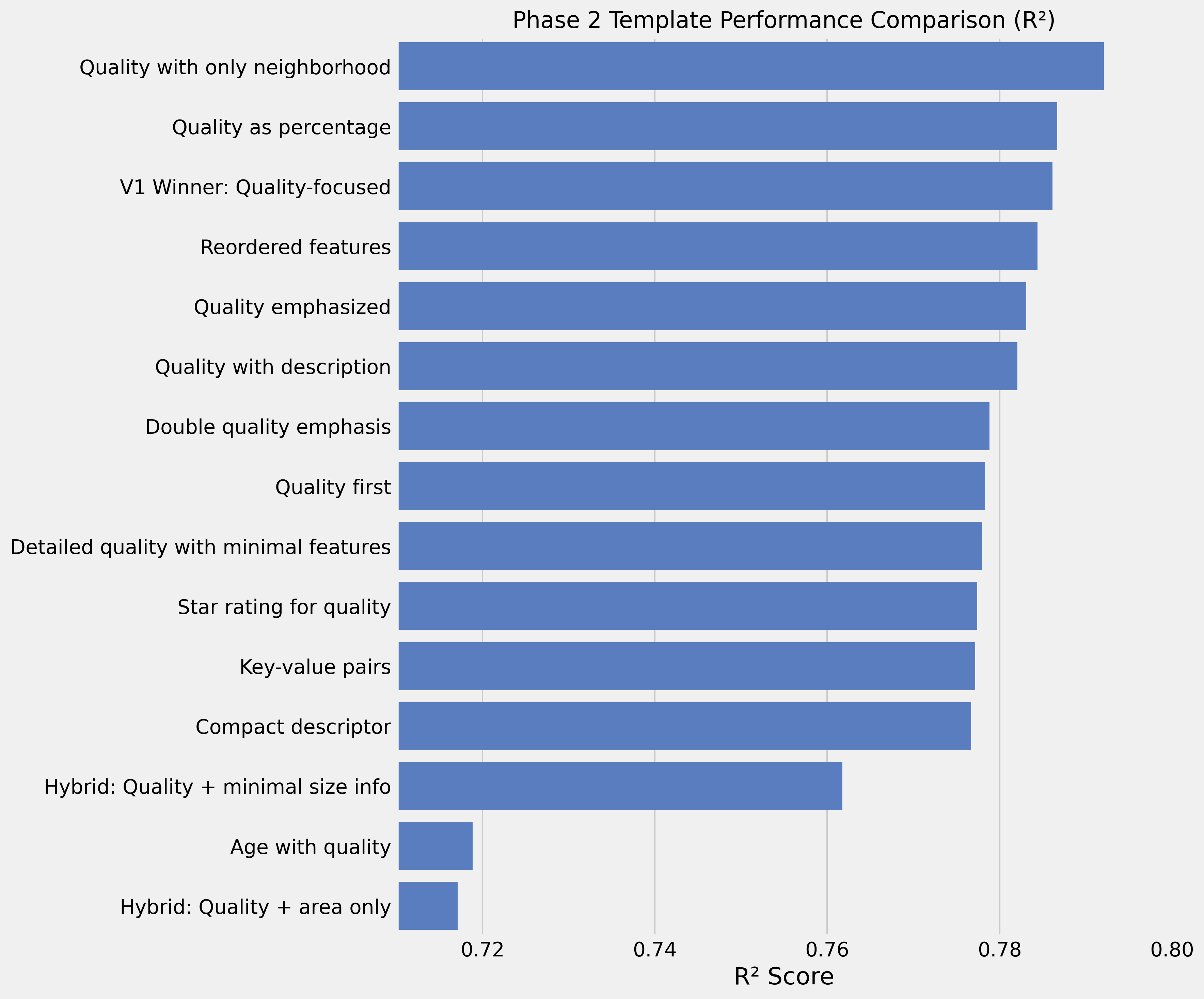
Fase 3: Seleção Estratégica de Features
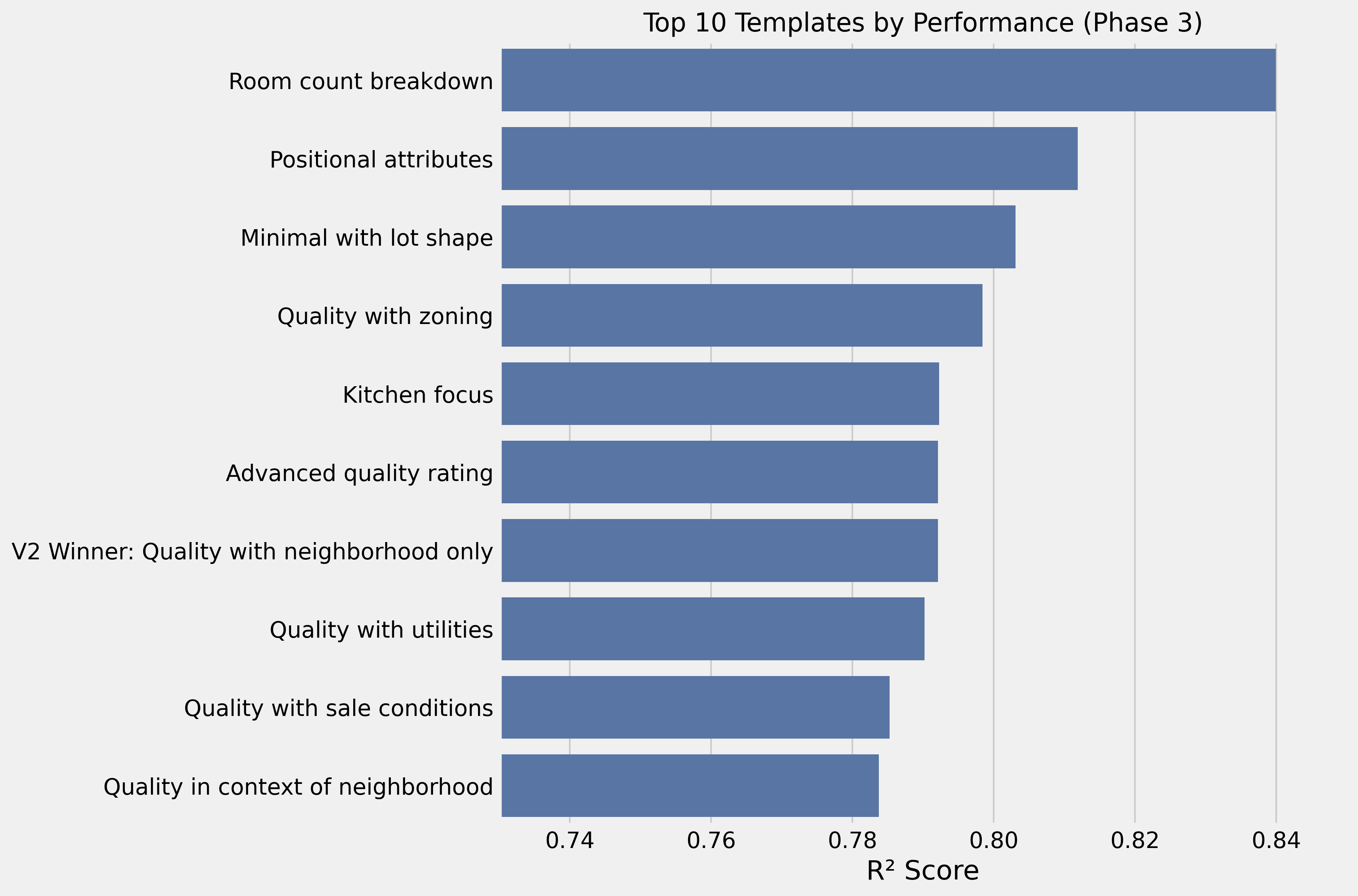
Adicionar contagem de cômodos ao template mínimo aumentou significativamente a performance:
Quality: {quality}/10. Neighborhood: {neighborhood}. Bedrooms: {bedrooms}.
Bathrooms: {bathrooms} (+{HalfBath} half). Basement baths: {BsmtFullBath} full +
{BsmtHalfBath} half. Total above-grade rooms: {TotRmsAbvGrd}.
Kitchens: {KitchenAbvGr}. Fireplaces: {Fireplaces}.R² de 0,84 — o melhor resultado até agora.
O Que Aprendemos Até Agora
Progressão de Performance
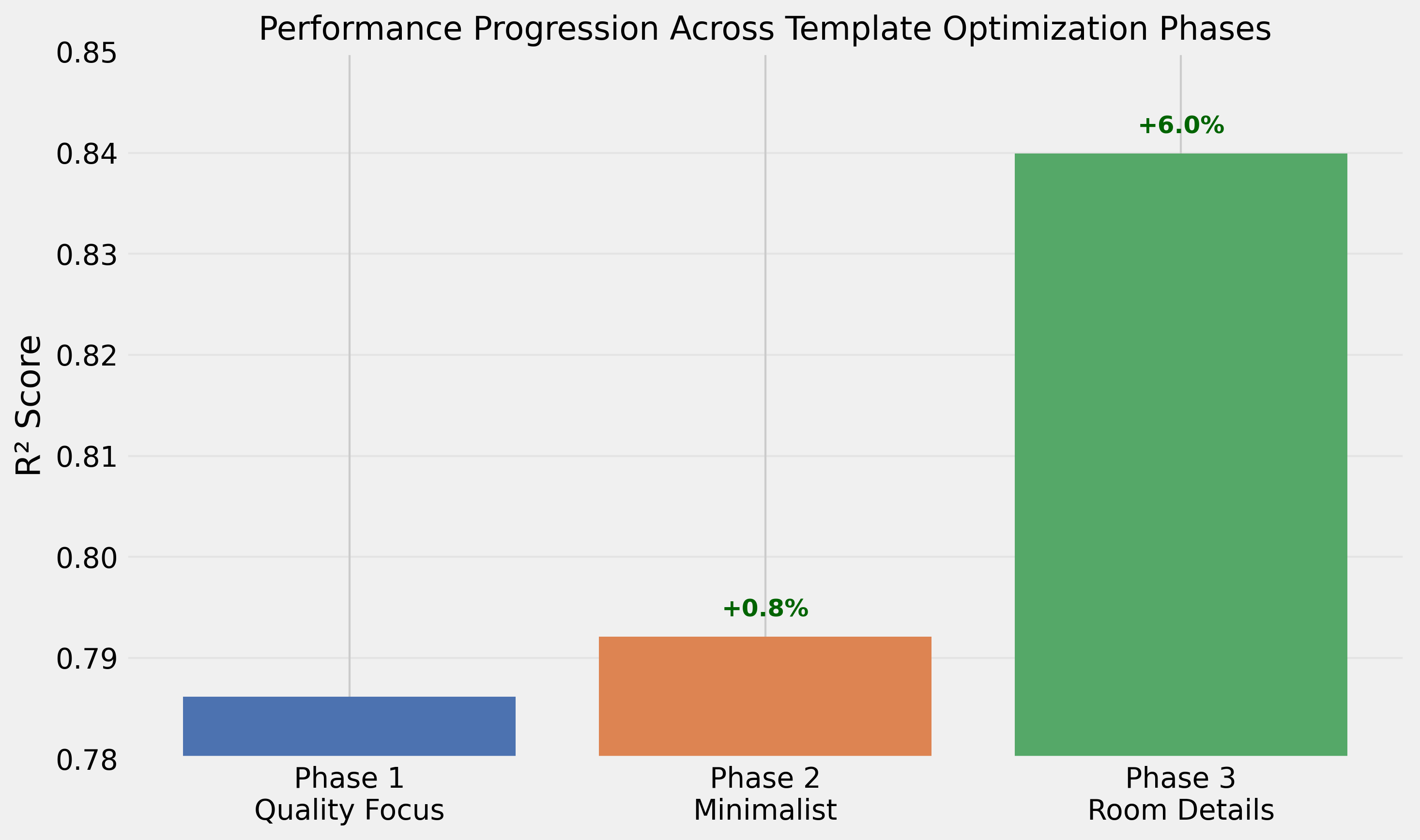
| Fase | Melhor Abordagem | R² | Melhoria |
|---|---|---|---|
| Inicial | Listagem padrão de imóvel | 0,731 | Baseline |
| Fase 1 | Foco em qualidade + features | 0,786 | +7,5% |
| Fase 2 | Qualidade + bairro apenas | 0,792 | +0,8% |
| Fase 3 | Detalhes de cômodos | 0,840 | +6,1% |
Insights sobre Estrutura de Templates
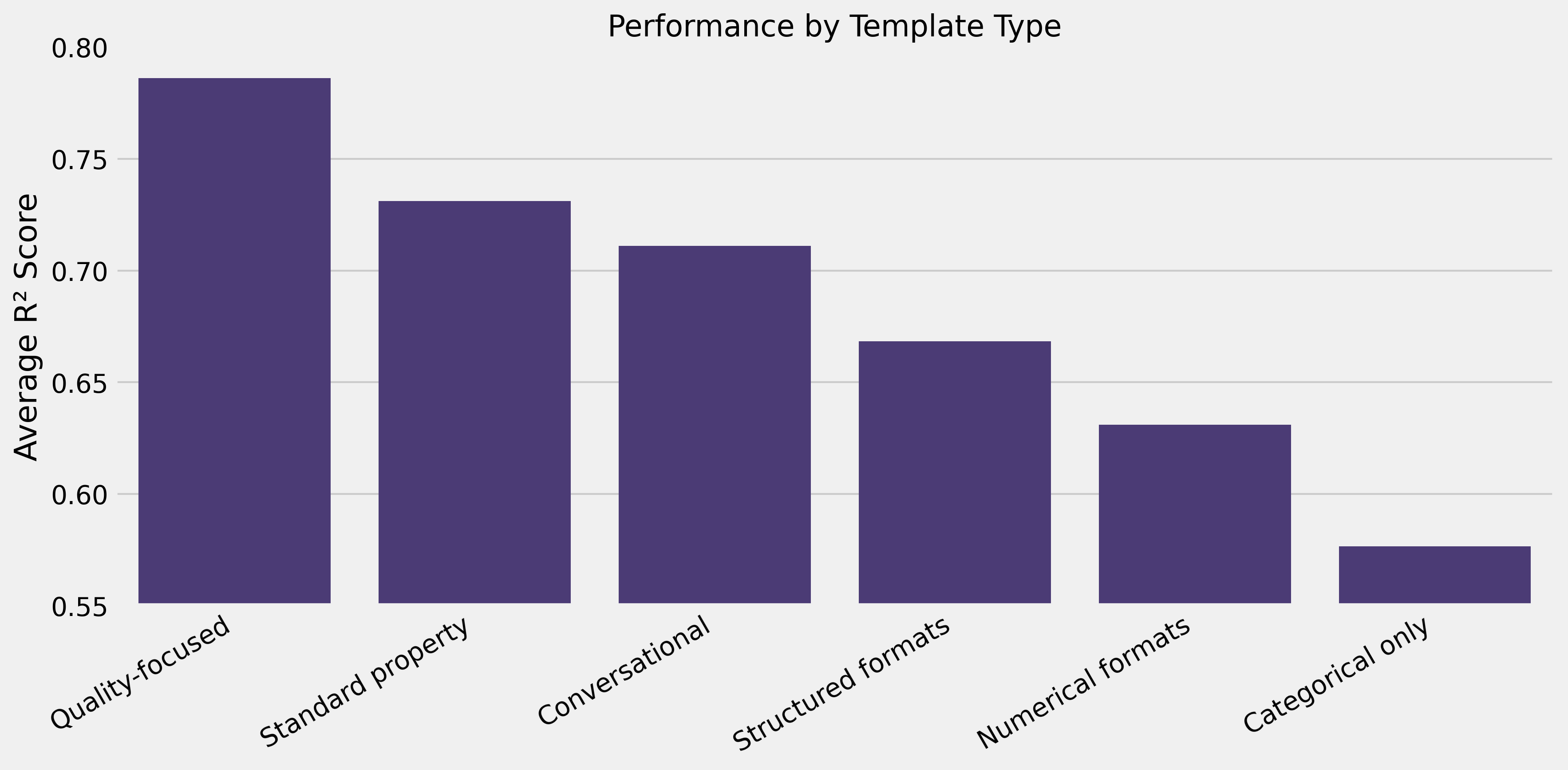
- Narrativas legíveis superam listas de dados: linguagem natural (R² 0,73–0,84) vs. valores separados por vírgula (R² 0,62) ou listas de palavras-chave (R² 0,67)
- Qualificadores contextuais ajudam:
quality rating: {quality}/10supera{quality}bruto - Ordem importa marginalmente: conteúdo idêntico reordenado mostrou pequenas diferenças (R² 0,784 vs. 0,786)
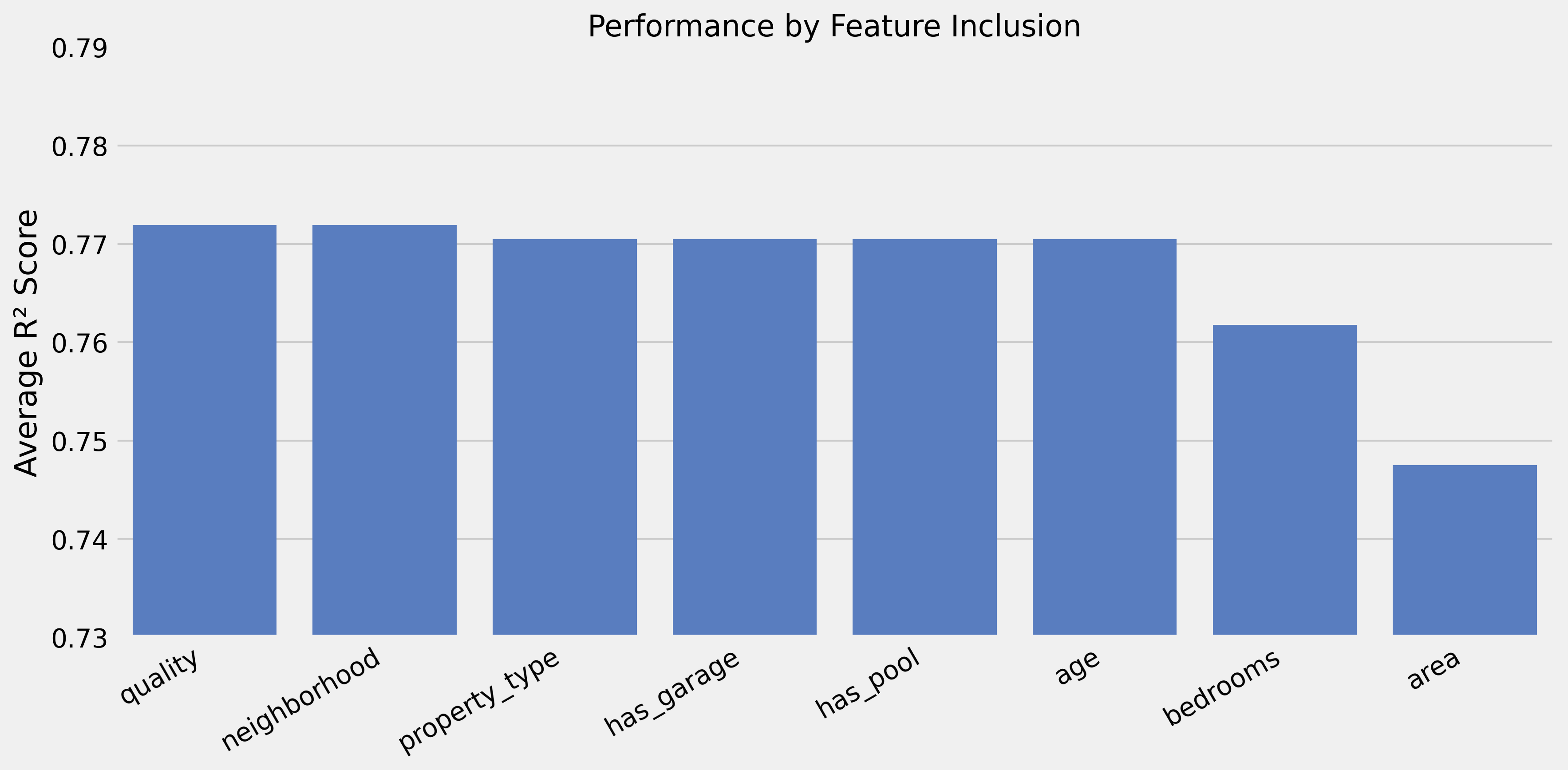
Efeitos de Combinação de Features
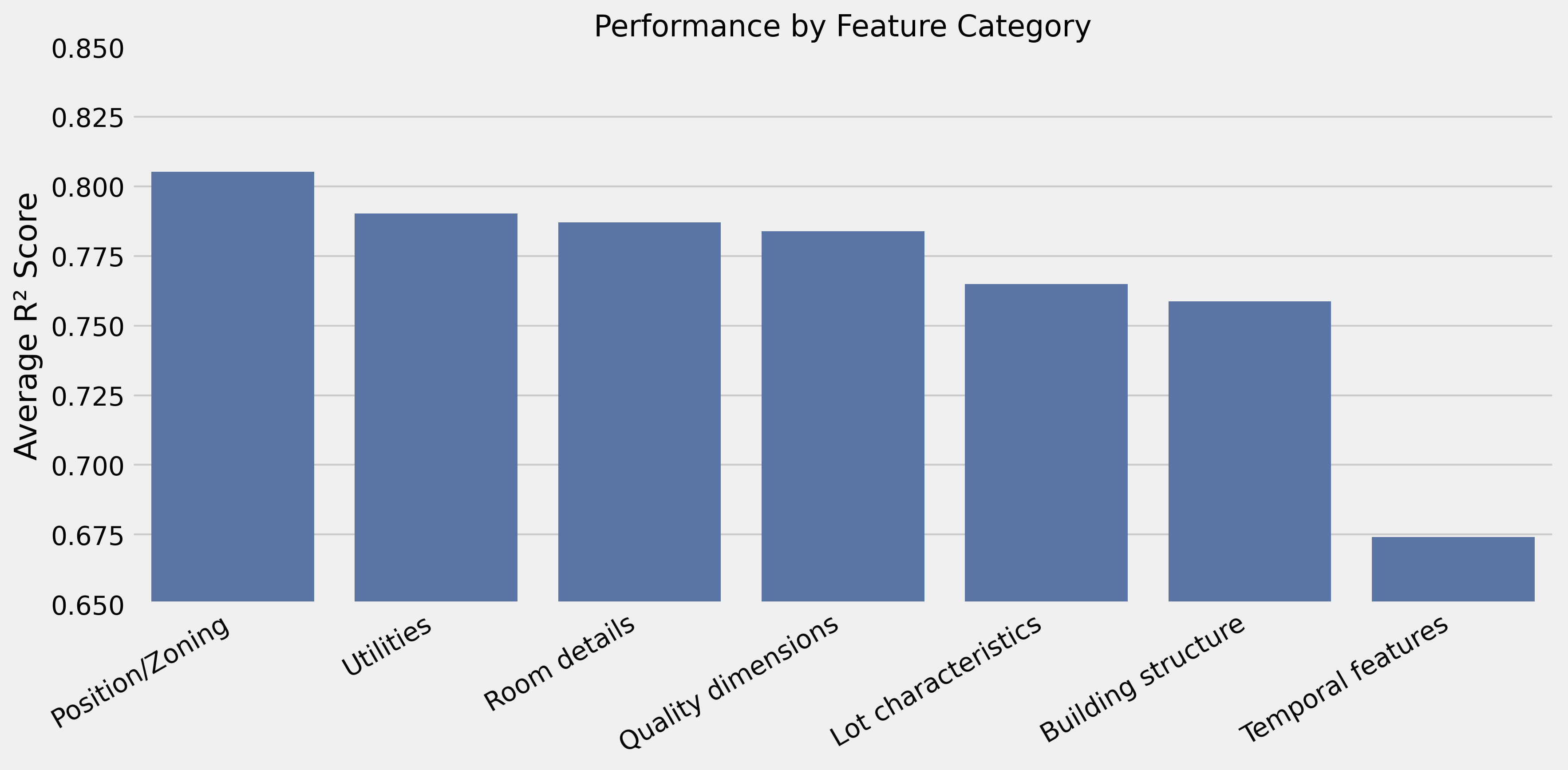
- Core: Qualidade + bairro → R² 0,792
- Adições de alto valor: Detalhes de cômodos (+0,048), forma do lote (+0,011), zoneamento (+0,006)
- Prejudica a performance: Informações de idade (−0,167), medidas de área (−0,078)
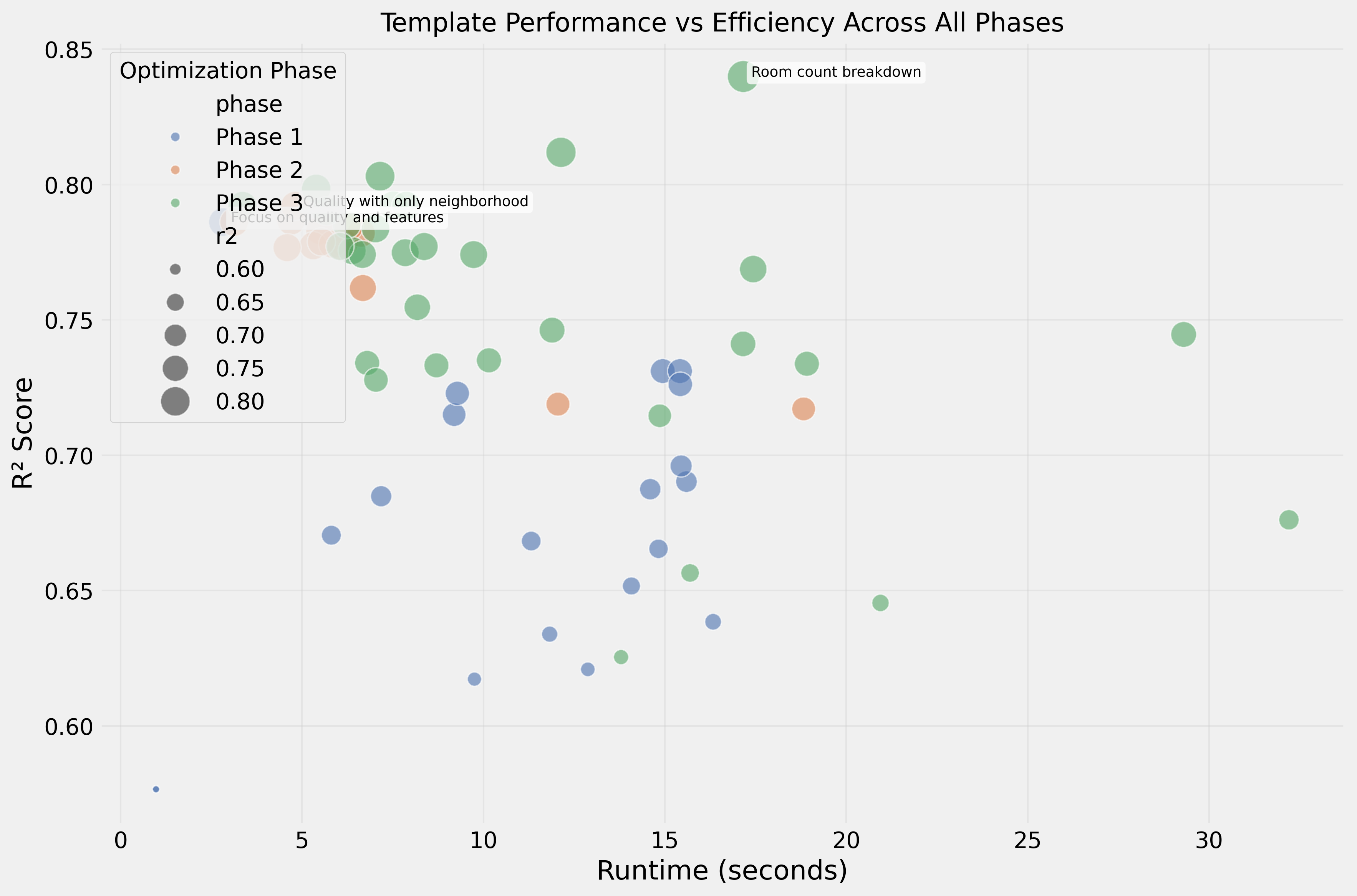
Eficiência
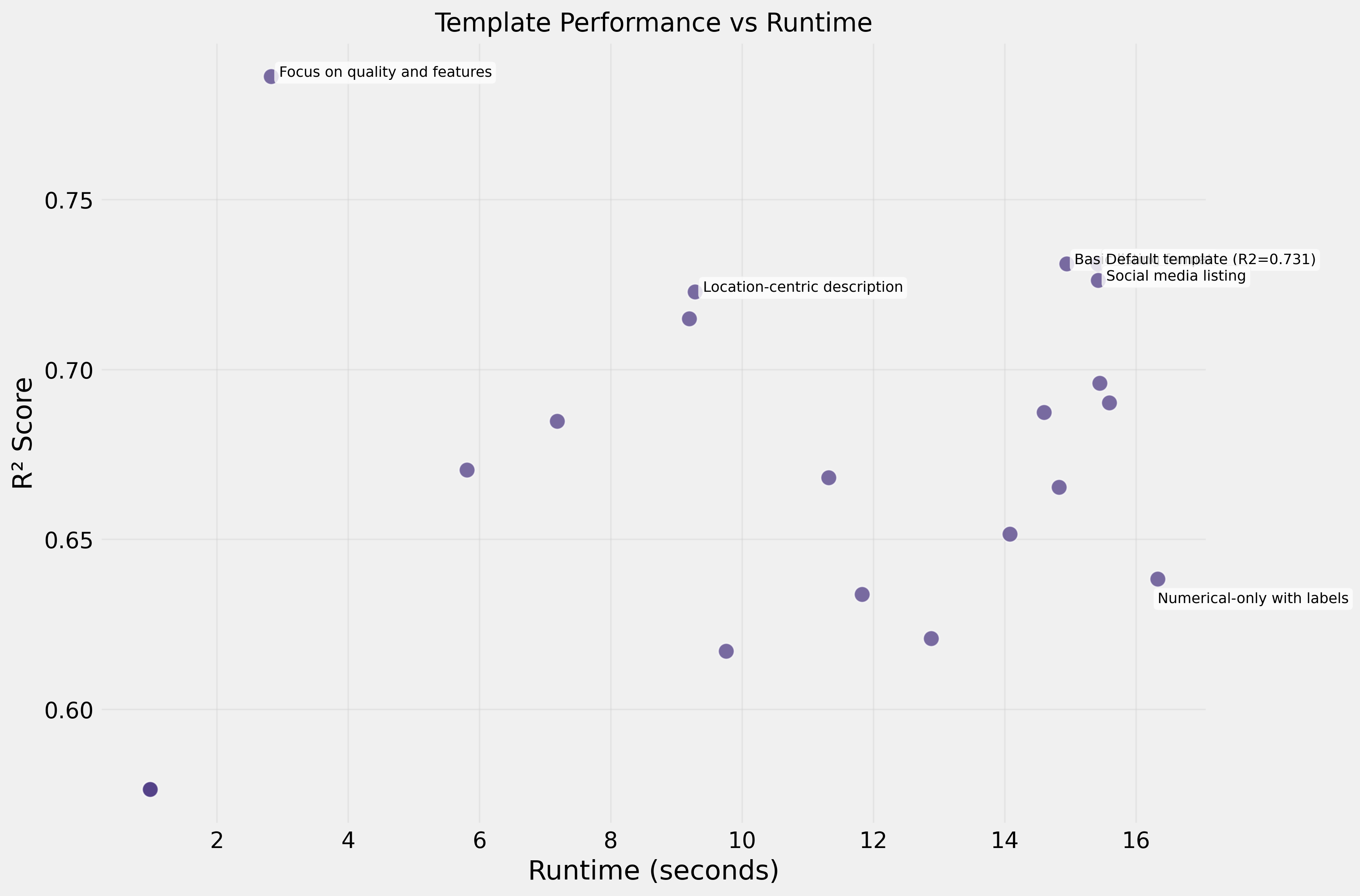
- Templates mais rápidos (3–5s): foco em qualidade + bairro → R² 0,792
- Templates mais lentos (15–32s): dados numéricos densos → R² 0,65–0,74
O template mais rápido processou 10× mais rápido enquanto alcançava melhor performance.
Desafios Atuais
1. Features Temporais Têm Dificuldade
Templates com datas e anos performaram mal. Modelos de embeddings têm dificuldade com relações temporais numéricas — um ano como “1985” não carrega o mesmo significado semântico para um modelo que para um analista imobiliário.
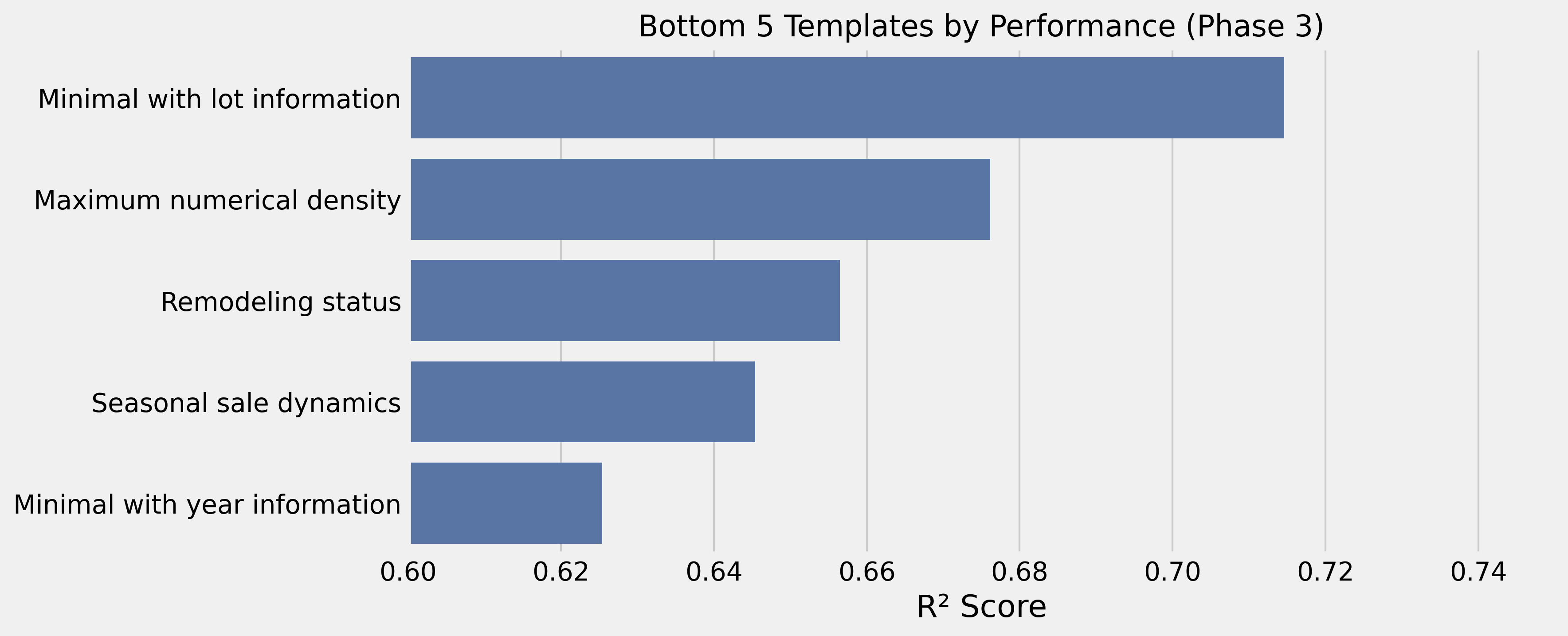
2. Templates Puramente Categóricos Faltam Contexto
Variáveis categóricas sem âncoras de qualidade performaram entre as piores (R² = 0,577). Precisam de indicadores numéricos para fornecer contexto significativo.
3. Templates Puramente Numéricos Perdem Semântica
Templates focados apenas em números também performaram mal (R² = 0,617–0,621). Modelos de embeddings não capturam relações matemáticas sem contextualização.
4. Templates Numéricos Densos Sobrecarregam o Sinal
Muitas medidas ao mesmo tempo criam um problema de ruído (R² = 0,676).
5. Templates Auto-Referenciais Causam Erros
Templates que referenciavam a variável alvo (sale_price) causaram erros — um lembrete para evitar vazamento de dados no design de templates.
6. A Lacuna Fundamental
A diferença entre a abordagem com embeddings (R² = 0,84) e a tradicional (R² = 0,97) reflete limitações fundamentais: modelos de embeddings foram projetados para linguagem natural, não para dados tabulares estruturados. Podem perder relações matemáticas precisas e tratar números como conceitos categóricos.
O Caminho à Frente
Pretendo aplicar esses aprendizados ao desafio de Universal Behavioral Modeling, que busca desenvolver representações de usuários que generalizem entre múltiplas tarefas preditivas — previsão de churn, recomendações de produtos e mais. A abordagem com embeddings mostra particular potencial ali, pois pode capturar o significado semântico das ações dos usuários de uma forma que a engenharia de features tradicional pode perder.
Conclusão
Ainda não igualamos a performance das abordagens tradicionais (0,84 vs. 0,97 R² no Ames Housing), mas a diferença está diminuindo. A jornada de dados tabulares para embeddings está apenas começando, mas o potencial de transformar a engenharia de features é enorme.
Fique ligado para mais atualizações à medida que esta pesquisa continua evoluindo!
Este post foi publicado originalmente no Medium.